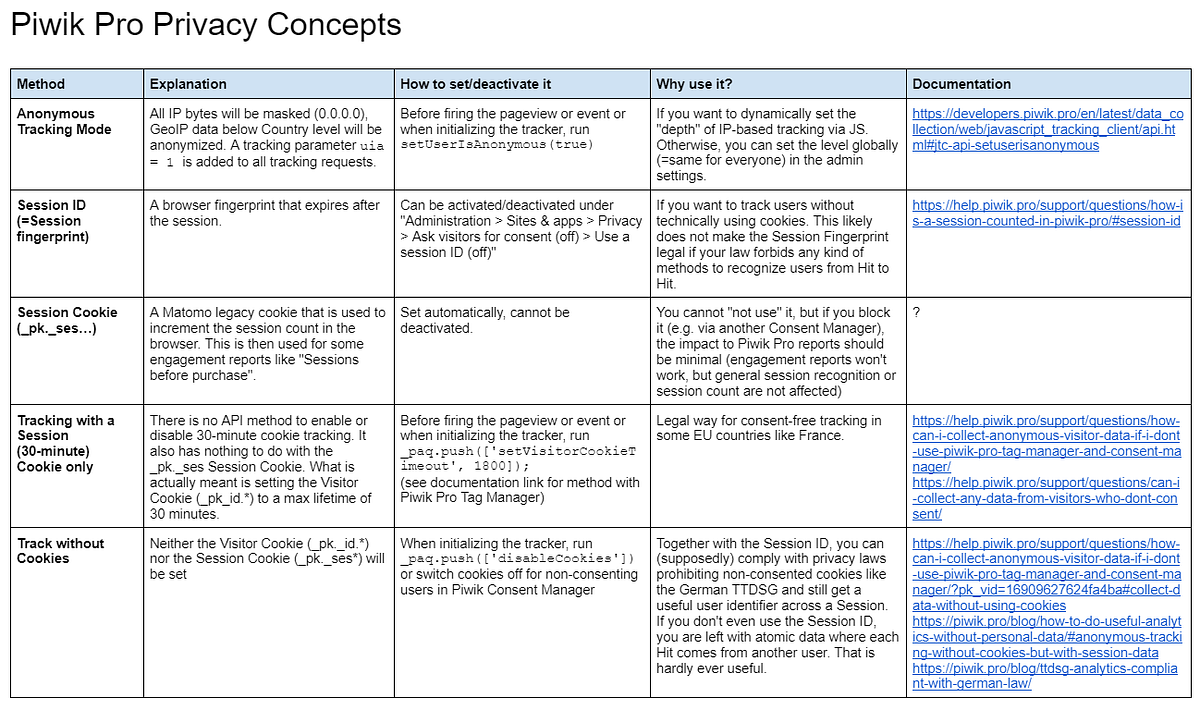
This workbook introduces the 'double three-layer' framework for event structures, organized by customer, product, and interaction layers. It's designed to help teams build a lean, analyzable event taxonomy that ties directly to business questions. Essential reading for anyone starting a tracking setup from scratch.
Timo Dechau May 25, 2025

























.png)